
This post is a part 1 of 2 in a series on tips and tricks on doing research on Late Modern English letters with the help corpora and other tools. Part 1 is about building your own corpus and concordancing software. Part 2 will go into detail on how to annotate the data in a corpus, i.e. adding linguistic information to your data. For example, keep editor notes in your data without making a whole new document and how to tag parts of speech.
Selecting a corpus containing personal correspondence is not always an easy task; you can only work with the limited material that is available. There are several projects and corpora on-line, for example this list with different historical English corpora and databases. That list is not exhaustive by any means and not all corpora in the list are accessible to the public. One way to avoid this problem is by building your own corpus.
If you want to build a letter corpus from a printed correspondence you can easily transfer a book into .txt files. This can be done by scanning the letters, saving them as image files, and running an OCR on the images. The OCR software will turn the images into machine-readable text. Often the software only allows you to save the text in a PDF or Word file, after which you can save it as a .txt file. Mind that even though this is a wonderful tool, it is not free of errors; always reread your texts to make sure they are exact copies of the original!
There are several OCR programmes on the market. I prefer to use ABBYY FineReader, a very user-friendly programme; unfortunately, not an open source programme. I looked up some alternative free OCR programmes for this post. If you don’t want to download software then Online OCR is a good alternative. I tested this one and the text was an exact copy. Cuneiform (scroll down and click English version set-up link if you want to download and install Cuneiform) and Simple OCR are simple and user-friendly programmes (the latter is not extremely accurate but you can easily spot the mistakes as these are marked in the document). A very accurate free OCR programme is Tesseract. This programme has been on my laptop for a month and I haven’t used it because I haven’t been able to find a good guide to set up this programme properly. You might want to give this one a try if you’re tech-savvy.
 If you want to analyse letters by means of a corpus linguistics approach concordancing programmes are indispensable. My favourite programmes are WordSmith Tools and Antconc. WordSmith is a programme with many great features. The basic features concord, keywords, and the wordlist are pretty straightforward and don’t need a lot of clarification. The statistics tab in the wordlist menu is a lifesaver for me as I am not the biggest fan of calculating things myself. The menu bar holds another interesting feature, namely ConcGram. This features finds clusters of words that often occur together in your corpus. It is not a simple feature – as you will have to build some things yourself – but worth the effort if you are interested in word clusters. An example of word clusters can be seen in the picture below.
If you want to analyse letters by means of a corpus linguistics approach concordancing programmes are indispensable. My favourite programmes are WordSmith Tools and Antconc. WordSmith is a programme with many great features. The basic features concord, keywords, and the wordlist are pretty straightforward and don’t need a lot of clarification. The statistics tab in the wordlist menu is a lifesaver for me as I am not the biggest fan of calculating things myself. The menu bar holds another interesting feature, namely ConcGram. This features finds clusters of words that often occur together in your corpus. It is not a simple feature – as you will have to build some things yourself – but worth the effort if you are interested in word clusters. An example of word clusters can be seen in the picture below.
 Antconc is a free concordancing programme (can be downloaded here). It is maybe a bit less straightforward in its use compared to WordSmith Tools. But Laurence Anthony has very detailed tutorials on youtube on how to work with this programme. I recommend to watch the tutorials before you want to start with this programme!
Antconc is a free concordancing programme (can be downloaded here). It is maybe a bit less straightforward in its use compared to WordSmith Tools. But Laurence Anthony has very detailed tutorials on youtube on how to work with this programme. I recommend to watch the tutorials before you want to start with this programme!
 This programme has the same basic features as WordSmith. The keyword list looks a bit different than the one in WordSmith. Antconc shows the words that are key in your corpus and not the negative keywords. However, if you tick the show negative keywords box in the settings this will all be resolved. Antconc also has a feature to show which clusters are salient in your corpus, named N-grams (see print screen below). You don’t have to do anything yourself to make this feature work.
This programme has the same basic features as WordSmith. The keyword list looks a bit different than the one in WordSmith. Antconc shows the words that are key in your corpus and not the negative keywords. However, if you tick the show negative keywords box in the settings this will all be resolved. Antconc also has a feature to show which clusters are salient in your corpus, named N-grams (see print screen below). You don’t have to do anything yourself to make this feature work.
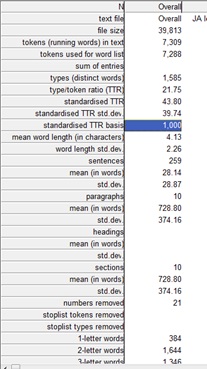
The one let-down of Antconc is that you’ll have to do the statistics yourself. The only numbers Antconc will provide you with are the number of types and tokens. I highly recommend this concordancing programme as it is free and you can work from your own computer.
If you have any other tips and tricks on how you go about your study in Late Modern English letters please comment in the comments section.

Extremely useful, Emily, thank you VERY much.